viagra, cialis, HOYGA fresco fresco!! me lo quitan de los manos.
Esto esta muerto, vamos a ver si escribimos más eh? fulanos!
Acabo de ver una noticia de ayer en la web de kaspersky donde dicen que han patentado un sistema para reconocer spam de imágenes. Al contrario de lo que cabe suponer, esta vez no usan un OCR sino que buscan más en el layout de la imagen para saber si esta puede contener texto y si es así compararla con determinadas signatures que tienen para ver si puede ser spam. Vamos a hacer ingeniería inversa de la noticia para construirnos en 5 minutos ese sistema, o bueno uno parecido… Empezamos.
Kaspersky Lab’s cutting-edge technology was designed to effectively detect text and spam in raster images without the need for machine recognition of images. This approach provides high-speed detection and can recognize text in almost any language.
Bien de este parrafo podemos inferir que efectivamente no pueden usar un OCR porque reconocen texto en cualquier idioma, y además rápido, cosas incompatibles para una solución antivirus. Por lo tanto tenemos que irnos a mirar un texto de una forma más global, por qué reconocemos un texto? . Veamos un ejemplo.
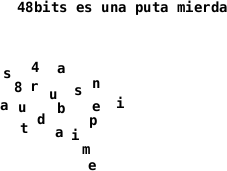
¿Que tienen en común el 99.9% del texto que puedas leer en un día? la horizontalidad. Es la forma natural, todos recordamos el correo ese que nos mandaban donde estaban cambiadas las letras pero que podiamos leer perfectamente. Pero eso sí, cuanta menos horizontalidad del texto, peor. En la nube de letras no podemos leer en claro nada. Entonces lo que está claro es que si no usan un OCR (no queda muy claro si lo usan al final de todo el proceso o no,ver siguiente parrafo ) el problema pasa de reconocer el propio texto a uno de segmentarlo.
The new patented technology is based on a probabilistic and statistical approach. Whether or not an image contains text is determined by the layout of the graphic patterns of words and lines as well as the content of the letters and words in those patterns. Dedicated filters ensure that the system is not affected by noise elements or the fracturing of text within images, while obfuscation techniques used in graphic spam such as warping and rotating are counteracted using a unique method of detecting text lines.
Bien, entonces tenemos una imagen que puede o no contener texto. Si tiene texto, es probable que haya sido generada por ordenador. A traves de un análisis de wavelets se podría llegar a distinguir si es o no una imagen generada por ordenador, pero también es algo costoso. Saltandonos ese paso y asumiendo que la imagen está generada por ordenador y contiene texto vamos a segmentar la propia imagen detectando sus bordes. Si algo tiene característico un texto es que sus bordes de alguna u otra manera están diferenciados del resto de la imagen. Para ello usaremos un algoritmo detector de bordes conocido como «Canny«, que usa un kernel gaussiano por lo que nos podemos quitar mucho del ruido que puedan habernos metido para ofuscar la imagen.
Y como hacemos para medir la horizontalidad de los bordes detectados? Pin pan: pues lo que se suele usar en Computer vision para detectar lineas,la transformada de Hough, las «Joulines» ( festival del humor )
Lo que vamos a hacer es detectar las lineas existentes en la imagen, y medir su pendiente que no es mas que m=(lines[n].x[1]-lines[n].x[0])/(lines[n].y[1]-lines[n].y[0] y para m definimos un threshold que queramos. Este threshold mediría la horizontalidad minima y máxima donde empezamos a tener dificultades para leer un texto.
Pero también tenemos que agrupar esas lineas en conjuntos de acuerdo a su proximidad, ya que un texto genera varias lineas muy proximas entre sí. Veamos.
Los rectangulos rojos marcan donde hay un texto con horizontalidad total, mientras que podemos ver las lineas de Hough que se generan. Pincha en la imagen para verla mejor.
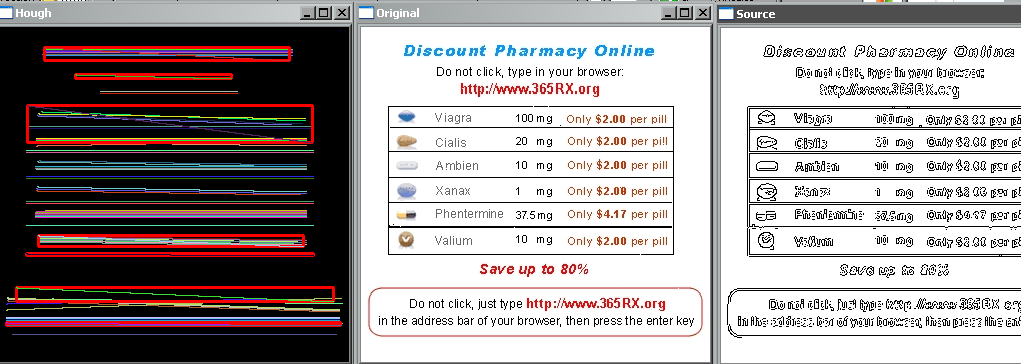
Ahora pongamos que tenemos una base de signatures donde decimos:
texto cuadrante superior izquierda
texto cuadrante inferior derecha
…
Comparando de esta manera el layout de la imagen podriamos tener un rapido sistema de detección de spam. Seguro que el método de kaspersky usa otras muchas cosas obviamente, pero bueno, esto es 48bits y yo he venido aquie a hablar de mi libro.